

Data engineering is more than just wrangling numbers; it’s creative problem-solving at its finest. From dealing with bottlenecks to modernising tech stacks, this field thrives at the intersection of innovation and practicality. To find out what it’s really like on the frontlines of data engineering, we sat down with one of Pwrteams’ seasoned experts. Spoiler: it's a world of tangled codebases, scalable solutions, and the occasional "anti-pattern" story.
Here’s what he shared about his journey, the challenges faced during a project for one of our amazing, long-term clients, and why data lakes (no, not the swimming kind) are still making waves.
Introduction & the project context
Q: Tell us about yourself and your role in this project.
A: I’ve been a data engineer since 2014, with a background in mathematics and a PhD in probability. My main tech stack includes Python, SQL, and cloud technologies. I’ve worked across AWS, Azure, and Google Cloud, and I have experience with tools like Databricks, PySpark, Delta Lake, and DevOps solutions.
In this project, I focused on developing and maintaining the data pipeline, designing solutions for bottlenecks, and implementing new features requested by the data modellers. A key part of my work involved refactoring the existing codebase and introducing proof-of-concept technologies like dynamic Terraform templates for Databricks workflows.


Selected tech stack elements used in this project.
Challenges & problem-solving
Q: What challenges did the client face that required a new data lake solution?
A: The main issues stemmed from outdated technologies, such as an Azure Data Factory setup, a tightly coupled codebase, and performance bottlenecks. These factors hindered scalability and efficiency.
Q: What were your biggest difficulties, and how did you tackle them?
A: One of the toughest aspects was untangling the existing codebase, which involved deep investigation and applying software engineering best practices. We also struggled with constantly evolving requirements from the data modellers, so we streamlined communication by documenting changes meticulously. The deployment process was another major obstacle; fixing it required extensive debugging and collaboration.
Technology choices & outcomes
Q: What technologies did you use, and why were they chosen?
A: We used a solid stack that included Python, PySpark, SQL, Databricks, Azure (Storage, SQL DB, ADF), Azure DevOps, and Airflow. These tools were already in place and well-suited for the project’s needs. Although modern tools like Terraform and DBT could have been beneficial, they weren’t approved due to process complexities.
Q: How did you integrate data from multiple countries into one system?
A: We used Azure Data Factory as an ingestion engine, which worked well within the Azure stack to handle the complexity of merging data from various sources.


Selected tech stack elements used in this project.
Q: What moments or achievements in the project made you proud?
A: Refactoring the tightly coupled codebase was particularly rewarding. It significantly improved maintainability and laid a better foundation for future development.
Q: What key lessons did you take away from this project?
A: I learned to recognise and avoid several anti-patterns. These are common practices that may seem functional initially but create long-term issues. Addressing these patterns early can prevent unnecessary complications.
Q: What’s an anti-pattern, and why is it important to avoid them?
A: An anti-pattern is a common but flawed approach to solving a problem. For example, creating a “big ball of mud” (a tightly coupled system) or a “god object” (an overloaded service handling too much) can lead to maintenance nightmares. Instead, following best practices like splitting responsibilities into small, manageable components ensures scalability and easier modifications.
What is an anti-pattern?
Q: If you could start over, what would you change?
A: I would prioritise implementing software engineering best practices from the outset and ensuring a smoother deployment process. These changes would allow more focus on development rather than firefighting.
The benefits of data lakes
Q: For a non-data person, how would you explain a data lake, and how does it compare to other solutions?
A: A data lake is like a giant digital storage room where you can keep all kinds of data, just like you would store different items in a warehouse. Imagine you have a warehouse where you can store anything from boxes of documents to crates of fruits, or even barrels of oil. Similarly, a data lake can hold various types of data, whether it's numbers, text, images, or videos.
Unlike traditional data storage systems, like organised filing cabinets with specific slots for each type of document, a data lake doesn't require a fixed structure. This means you can throw in data as it comes, without worrying about fitting it into a specific format. This flexibility makes storing and managing large amounts of diverse data easier.

Source: https://www.figma.com/@samanxsaybani"
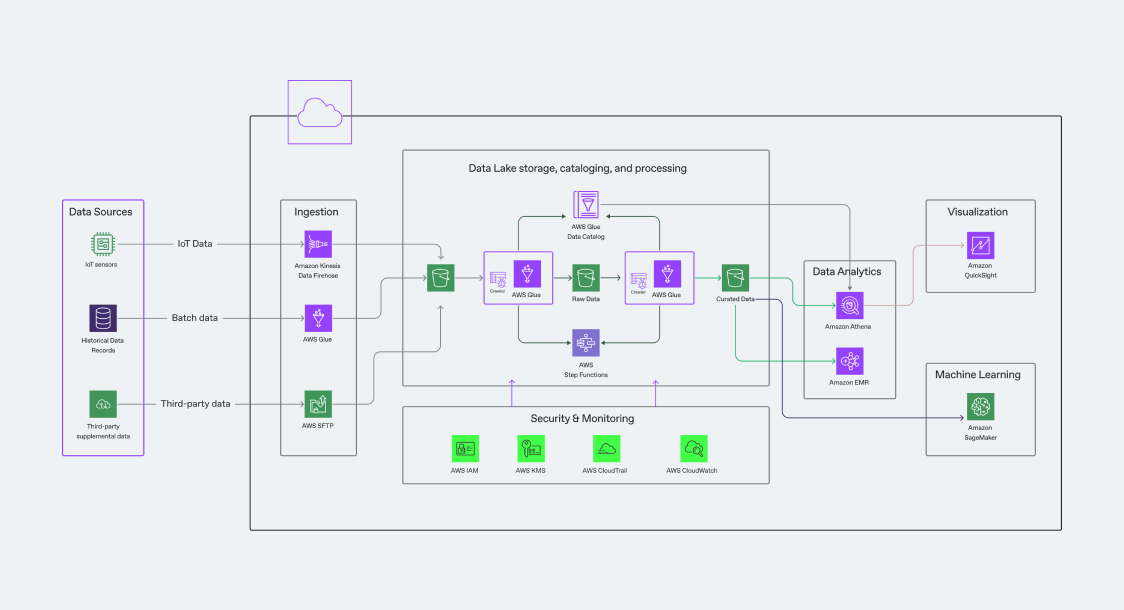

The main benefit of a data lake is its ability to handle all this data in one place, making it easier and cheaper to store everything together. However, just like in a warehouse, you need the right solutions and processes to sort through and use the data effectively. This is where additional processing tools come in, helping to organise and analyse the data so that businesses can make better decisions.
A data lake is a modern way of generally handling data, which is quite common and convenient. It is not the latest technology, but it is a workable solution.
Q: What would be the latest type of solution?
A: For example, data meshes. A data mesh is like microservices for data platforms. There are certain connections, so there are different data teams, and every team is responsible - does the job it is responsible for - and they intercommunicate. It can also include certain data lake storage. But this concept, I would say, should not be implemented everywhere because it's really for certain complex enterprises that need data for specific purposes.
But a data lake was the simplest and most efficient solution in the given case.
What is a data mesh?
Q: How does a data lake differ from traditional data storage, and what are its main benefits?
A: Unlike traditional data storage systems, which rely on predefined schemas, a data lake can store structured, semi-structured, and unstructured data. This flexibility makes it ideal for handling large, diverse datasets. In this project, a data lake reduced processing times significantly, which was a key performance indicator.
Q: What challenges do companies face when setting up a data lake?
A: Common issues include managing cloud infrastructure, optimising costs, ensuring data security and governance, and designing a scalable architecture that aligns with business needs.
Q: How do cloud-based data lakes compare to on-premises solutions?
A: Cloud-based solutions are often easier to implement and maintain, with scalability and cost advantages due to pay-as-you-go models. However, on-premises solutions can offer better security and, in some cases, lower costs if the organisation has the resources to manage them effectively.
Data lake vs. data warehouse?
Data engineering trends
Q: What trends or topics in data engineering excite you most?
A: The general trend is AI everywhere. Of course, people talk about it - data people, DevOps people, software engineers - people want to move to this. Actually, I had some experience in data science and then switched completely to data engineering.
For my preferences, it's data platform topics - data platforming. It's a more advanced area for a data engineer; you have to set up data engineering together with infrastructure. Let's say it's data engineer plus DevOps. So, to configure it to run on certain containerised orchestrators - that is, Kubernetes, for example. That's where I'm focusing my personal development.
What is data platforming?
A big thank you for taking us behind the scenes of this challenging yet rewarding project. Your expertise and insights remind us why data engineering is both an art and a science.
Conclusion
Data engineering is an exciting yet challenging field that requires not only technical expertise but also creativity and adaptability. If you enjoyed this interview, don’t miss our other blog articles exploring trends, challenges, and innovations in the tech world. Whether you’re curious about AI, cloud solutions, or DevOps, we’ve got insights that can help you stay ahead.
And if you’re looking for a skilled data engineer or any other tech professional to strengthen your team, we’d love to hear from you. At Pwrteams, we specialise in connecting businesses with top talent who thrive on tackling complex challenges.
Let’s make your next data project a success. Get in touch today!


